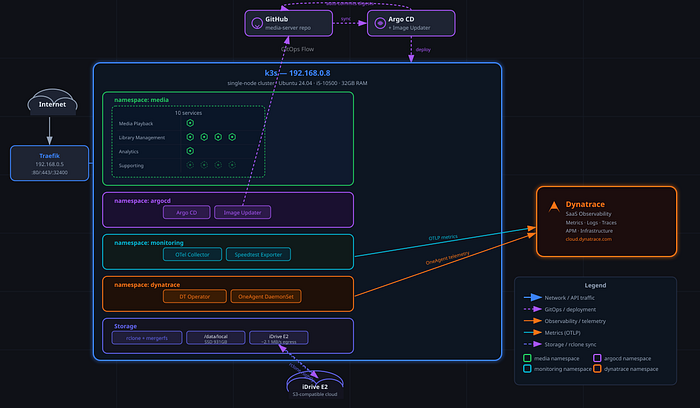
There's a Lenovo ThinkCentre sitting on a shelf in my home office. Intel i5 processor, 32GB RAM, 1TB SSD, Intel UHD 630 for hardware transcoding — nothing special. What one week of vibe coding with Claude Code produced on it is a different story: ten containerised services — Plex for media playback, Radarr, Sonarr, and Lidarr for library management, Tautulli for analytics, and four supporting services — deployed via GitOps on k3s, kept up to date by Argo CD Image Updater so every image digest change is an automatic git commit, and monitored end-to-end by Dynatrace with an OTel pipeline pulling rclone transfer metrics and speedtest results in real time.
But here's the real story. I'd been running a version of this stack on bare metal for years. It worked fine — until I needed new hardware. Suddenly, I was staring at weeks of work: half the configuration lived in my head, the rest scattered across notes and muscle memory. This is the trap every engineer knows with side projects. Hardware fails, you move on, a year passes, and the mental model you had is gone. Rebuilding from scratch on a system this complex isn't a weekend job.
So getting new hardware became the forcing function. Instead of copying files and hoping nothing broke, I decided to use it as an opportunity — learn Claude Code, and build something I could actually restore. Not just "get it running again" but restore it properly: documented, automated, reproducible on any hardware, from backup, by someone who'd forgotten half the details. That's the bar I was working toward.
I built it in evenings over one week. My Kubernetes knowledge going in: theoretical. I knew what a pod was. I had never written a manifest.
The obvious assumption: you let Claude Code build it for you. That framing is wrong, and I think it's worth explaining why — especially now, when companies are handing down "AI-first" mandates and engineers are trying to figure out what that actually means for how they work.
TL;DR
• The real goal wasn't building a media server — it was escaping the fragility trap: a system so manually configured that hardware failure meant weeks of rebuilding from memory
• Zero Kubernetes experience to a GitOps stack in one week of evenings. AI compressed the learning curve; domain knowledge drove every meaningful decision.
• AI burned an entire context window going in circles on one problem. A 10-minute conversation with a human expert fixed it. Knowing when to stop is still an engineering skill.
What "Vibe Coding" Actually Means
The term has earned some eye-rolls, mostly because people picture someone typing "build me an app" into a chatbot and shipping whatever comes back. If that's your definition, sure, dismiss it. But that's not what I did, and it's not what the term means to anyone who has actually tried to build something non-trivial this way.
A note on tooling before the detail: Claude Code is not an IDE completion tool. It's an agentic environment — it has full access to your repo, can run shell commands, reads and writes files, and maintains context across a project through a conversation interface. If you've used GitHub Copilot, you've experienced autocomplete that understands your codebase. Claude Code is a different category: you have an architectural conversation with it, and it can execute directly against your codebase. The ceiling is higher, and so is the cost — a week of heavy agentic sessions runs to tens of dollars in API usage. Worth knowing before you start.
What I practiced was an iterative, conversational workflow. I drove the intent and the architecture. Claude Code handled the implementation details, the boilerplate, and the cognitive load of holding ten services' worth of configuration in context at once. I reviewed the architectural decisions and pushed back when something was wrong. I didn't audit every line of the Sealed Secrets controller manifest — I trusted the official release for that — but every decision that shaped how the system works was mine.
The key mechanism was CLAUDE.md — a living architecture document committed to the repo that Claude reads at the start of every session. Think of it as shared memory: a document the AI reads before every conversation so it never loses track of what you've already decided. Hardware specs, storage layout, network topology, and every design decision with the reasoning behind it. Whenever I pushed back on something, and we landed somewhere better, that answer went into CLAUDE.md. By the end of the week, it was the single most accurate description of the system that existed anywhere — better than any wiki, because it was updated in real time as decisions were made.
Claude Code can simulate failure scenarios, reason through what breaks first on an empty system, and read pod events to diagnose a restart loop at midnight. What it can't do is measure your environment, tell you when something feels off, or know what you actually care about. Those things don't live in any model. They stayed with me.
What Does a Week of Vibe Coding Actually Produce?
Hardware: Lenovo ThinkCentre, Intel i5 processor, 32GB RAM, 1TB encrypted SSD, Intel UHD 630 for hardware transcoding. Ubuntu 24.04 with full-disk LUKS encryption and Dropbear SSH for remote unlock at boot.
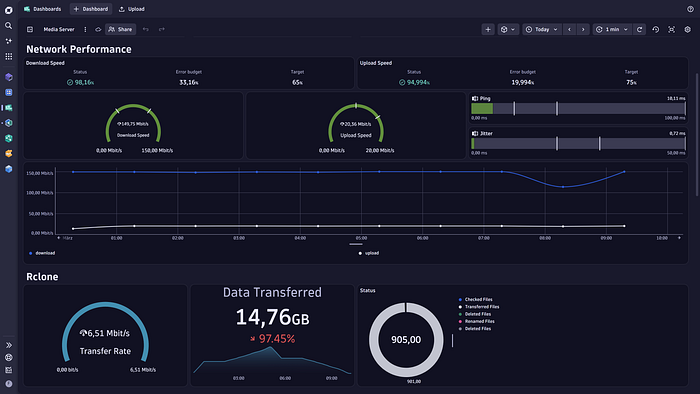
Storage: I needed media stored on local SSD and in the cloud to look like a single library. rclone handles the cloud connection to iDrive E2; mergerfs unions the local SSD and the cloud mount into a single /data/media path that Plex reads without knowing or caring where files actually live. VFS cache capped at 20GB on local SSD to keep hot content fast. Measured egress from iDrive E2: ~2.1 MB/s. That number matters — I'll come back to it.
Compute: k3s — a lightweight Kubernetes distribution suited to single-node setups. Ten media services, each with resource limits tuned to the hardware, and all three probe types configured (startup, liveness, readiness). k3s is deliberately not high-availability; it's one machine, one control plane. That's a trade-off I accepted in exchange for simplicity — and one that the backup and restore pipeline is designed to recover from quickly when hardware eventually fails. Plex gets 4 CPU cores and 8GB RAM at the limit. /dev/dri/renderD128 mounted into the container for hardware transcoding, LIBVA_DRIVER_NAME=iHD set in the env so the iHD VA-API driver actually gets picked up.
GitOps: Argo CD v3.3.4 and Image Updater v0.15.1. The repo is the source of truth. Image Updater polls registries, pins new digests in each service's kustomization.yaml, and commits back to main automatically. My git log has entries like build: automatic update of plex — that's the cluster telling me what it changed, not me doing anything. For a solo project, direct commits to main work fine. In a team context, you'd route these through pull requests with approval gates — the mechanism is the same, the governance layer sits on top.
Observability: Dynatrace Kubernetes Operator v1.8.1 in cloudNativeFullStack mode (OneAgent DaemonSet on the node), OTel Collector scraping rclone's Prometheus /metrics endpoint and the speedtest exporter, logMonitoring DaemonSet for pod logs. Daily backups go to a separate machine on the home network via rclone; the backup script also runs config drift detection and surfaces warnings to Dynatrace. Restore dry-run runs automatically on the 1st of every month at 04:00.
How It Actually Went
Day One: Ten Services, Zero Prior Manifests
The media server was running in a couple of hours on day one. Ten containers, health probes, resource limits, and hardware transcoding configured. I had never written a manifest before that evening.
The speed is the easy part to point at, but it's not the interesting part. What surprised me was how much I learned in the process. Claude didn't just generate YAML — it explained every decision. I asked why Recreate instead of RollingUpdate for stateful services and got back a clear answer: two instances of Radarr writing to the same config directory at the same time will corrupt the database. I asked what storageClassName: "" was doing in the PersistentVolume definition and got an explanation of how k3s's local-path provisioner auto-binds PVCs and why you opt out of it to control binding yourself. I wasn't reading documentation top-to-bottom. I was building something and asking why at each step, and getting answers that were scoped to exactly what I was building.
The first real debugging moment: a Bazarr pod in a permanent restart loop. kubectl describe pod wasn't immediately illuminating. Claude read the manifest, read the pod events, and found it: the liveness probe was hitting /ping, but Bazarr with auth enabled returns 401 there, which the probe treats as failure, which triggers a restart, which tries the probe again. On loop. Fix was switching to a TCP probe — seconds once the cause was clear. Without help, I'd have been digging through Bazarr docs and Kubernetes probe configuration for hours.
Measuring Reality: When the Default Was 8x Too Slow
The rclone tuning story is the clearest example I have of why AI can't replace engineering judgment.
The initial VFS config used ReadAhead=128MB. Sensible default — the idea is you buffer ahead of playback so network hiccups don't interrupt the stream. Problem: iDrive E2's actual egress to my home is ~2.1 MB/s. At that speed, 128MB takes 128 ÷ 2.1 = 61 seconds to buffer before playback starts. I was sitting in front of a blank screen for a minute every time I tried to watch something.
Claude set ReadAhead=128MB because it's the right default for a fast connection. It had no way to know my actual egress speed — that only exists in my environment, and only if someone measures it. I measured it, did the math, and dropped the value to 16MB. At 2.1 MB/s, 16MB buffers in 7.6 seconds. Eight times faster. The math is straightforward once you have the right input. The right input required a human who could notice it felt slow and go find out why.

The Argo CD Migration: One Day, One Architecture Decision
There were a handful of architectural moments where I pushed back. How logs were structured. Where config belonged — ConfigMap versus environment variable versus a mounted file. How manifests should be organised before the Argo CD migration. My approach every time: "Here's an alternative. Walk me through the tradeoffs." Not "you're wrong" — just forcing a comparison. The outcome was consistently better than either starting position. Claude brought Kubernetes conventions and implementation knowledge; I brought an understanding of how this system would actually be operated. Both mattered.
The Argo CD migration itself happened on one day, about midway through the week. Moving from flat manifests to per-service subdirectories — each with its own kustomization.yaml — looks like a refactor but it's an architecture decision. It unlocked granular Argo CD Applications (roll back one service, not the whole cluster), Image Updater digest pinning scoped per service, and a git history where you can trace which commit updated which image. Claude designed the structure. I signed off on it.
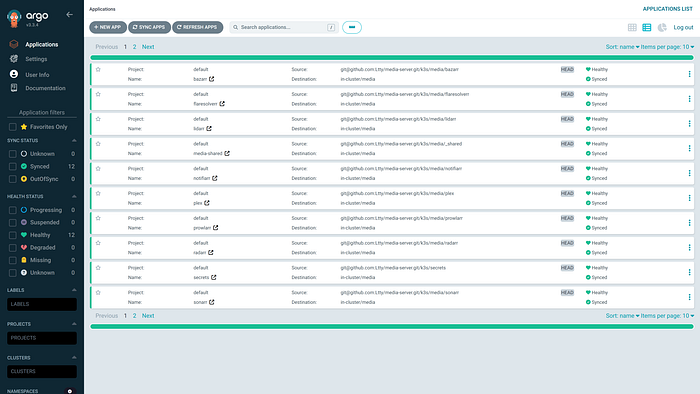
One thing that bit us: remote URLs in kustomization.yaml don't work inside Argo CD's kustomize engine. The Sealed Secrets controller was initially defined as a GitHub release URL. Argo CD can't fetch from external URLs at apply time — it expects everything in the repo. We downloaded the 413-line manifest and committed it locally. GitOps means git is the source of truth. Not a URL. Not "I'll fetch it at apply time." The repo.
Where Claude Ran Out of Road: The Dynatrace Operator Problem
The observability story is the one I'm most honest about, because it's where AI didn't just hit a wall — it went in circles until it ran out of road.
When I joined Dynatrace, I installed a standalone OneAgent directly on the bare metal host to understand the technology. That worked fine: host metrics flowing, rclone transfer stats coming in via an OTel Collector. What I didn't have was Kubernetes-native context — pod logs not correlated to the cluster, no service-level metadata in Dynatrace.
Reasonable fix: add the Kubernetes Operator with applicationMonitoring mode and enable the logMonitoring DaemonSet. The docs describe this in a few steps. I followed them. The logMonitoring pod wouldn't start — exit 128, bootstrap binary not found. The Operator was creating the DaemonSet but not mounting the CSI code module into the init container. Whether that's a bug or expected behaviour with applicationMonitoring, I couldn't tell.
This is where it got expensive. Claude Code spent an entire session — the whole context window, all the tokens — patching manifests, adjusting the DynaKube configuration, trying variations. Nothing worked. And the more I watched it iterate, the stronger my gut feeling became: this isn't a manifest problem. Something is architecturally wrong and we're fixing the wrong thing.
I stopped the session and messaged a Dynatrace Operator developer directly. What came back was useful: the combination I was running — bare metal OneAgent, Operator with applicationMonitoring, logMonitoring DaemonSet — had never been intended or tested together. It wasn't a documented failure mode; it was just an untested path that nobody had thought through. The recommendation: go cloudNativeFullStack, drop the bare metal agent, get everything from a single managed installation.
I tried to install CNFS. Got an explicit conflict error — you can't run a cloudNativeFullStack DaemonSet and a bare metal OneAgent on the same node, the install refuses. Uninstalled the bare metal agent. Applied the CNFS DynaKube manifest. Everything came up. Pod logs correlated. Full Kubernetes metadata in Dynatrace. A full day of Claude burning tokens on the wrong problem, solved in one conversation with the right person.
The thing Claude couldn't have told me wasn't in any public documentation. The architecture combination was untested. No amount of manifest iteration was going to fix that. Only someone who knew the internals could surface it.
End state: OneAgent DaemonSet on the node, pod, and host metrics in Dynatrace, rclone transfer stats and speedtest results coming in via OTel, pod logs collected, and config drift surfaced daily.
Where Does AI Actually Break Down?
I want to be direct about this, because most "AI won't replace engineers" takes are either vague reassurance or defensive overreach. Here's what I actually ran into.
AI can't measure your environment. It doesn't know your cloud provider egresses at 2.1 MB/s instead of 150Mbit. It doesn't know your disk latency or your network topology. The config it generates is structurally correct — calibrating it to your reality is on you.
AI doesn't know when something feels wrong. 61 seconds is a number. "This is unacceptable" is a judgment. That gap is engineering experience, and no model fills it.
AI can't debug what's not documented — and it won't always tell you when it's stuck. Claude burned an entire context window on the logMonitoring problem, iterating on manifests for an architecture combination that was never tested. It kept trying because that's what it does. It had no way to know the problem wasn't in the manifests. I had to be the one to notice we were going in circles and pull the plug. Recognising when to stop and escalate is still a human judgment call.
AI has no architectural taste. ConfigMap versus Secret versus env var. Where config lives. What things are called. These choices seem small and compound badly. Getting them right requires the kind of judgment you develop over years of maintaining systems, not from reading specs.
AI can't know what you actually want. "Set up observability" covers a lot of ground. That Dynatrace-native was the right answer in my case — because I work there and know the architecture — was information only I had. The AI executed on the intent I gave it. The intent was mine.
What Is AI Actually Good For?
Here's what actually impressed me after a week of using it for real infrastructure work.
It compresses learning curves in a way nothing else does. Zero hands-on Kubernetes experience to understanding kustomize overlays, Sealed Secrets, Image Updater git write-back, k3s service networking, and PersistentVolume binding in one week — not by reading docs, but by building something and asking why at each step. The feedback loop is tight because the context is specific to what you're building.
It reasons about failure modes you don't have a live environment to test. The monthly restore dry-run — restore.sh --dry-run, 1st of every month at 04:00 — was designed entirely by reasoning about what breaks first on an empty system. No empty system required. Claude worked through dependency ordering, partial restore scenarios, what a broken backup actually looks like. The design came from a conversation. That dry-run has already caught a broken Bazarr backup path I'd changed without updating the script — silently, at 4am, logged to Dynatrace before I'd even had coffee. That's the thing about building resilience with AI: you're not just fixing today's problems, you're reasoning about the ones you haven't hit yet.
It holds context that would overwhelm a single working session. CLAUDE.md becomes the project's memory. Every decision documented, every tradeoff recorded. After a day away I didn't need to rebuild state — it was all there. A week-long project that would normally live in one person's head had a written record of every meaningful choice.
And yes — the midnight debugger. Pods restart-looping at 11pm, a tool that can read the manifest, read the pod events, tell you exactly why /ping returns 401 with auth enabled, and hand you the fix. The alternative is you, Stack Overflow, and the slowly dawning realisation you're going to be awake for a while.
AI-First Doesn't Mean AI-Only
If you're an engineer at a company that has handed down an "AI-first" directive, you've probably noticed that the directive doesn't come with a definition. And the unstated implication — sometimes stated outright — is that human judgment is the bottleneck to be eliminated.
That's backwards.
The right frame is simpler: AI removes the friction between what you understand and what you can build.
I understood Kubernetes conceptually. I understood my storage constraints. I knew what 61 seconds felt like. I knew Dynatrace's architecture because I work there, and that knowledge was the thing that eventually unblocked the Operator conflict. What I didn't have was the syntax, the boilerplate, the kubectl muscle memory, the ability to hold ten services in working memory while configuring the next one.
AI gave me all of that. My judgment gave it direction.
The engineers who'll get the most out of these tools aren't the ones who hand everything over and accept what comes back. They're the ones who engage critically, bring what they know to the conversation, challenge the tool when something doesn't add up, and know when a problem needs a human expert. The Dynatrace Operator story is the proof: AI was useful for nearly everything in this project, and there was exactly one problem it couldn't solve. Knowing that difference — and picking up the phone — is still an engineering skill.
The media server runs. Every image update is a git commit. Every backup is verified monthly by a dry-run that runs without me. Dynatrace has the full picture. A week of evenings, one consumer PC, someone who'd never written a Kubernetes manifest.
And the fragility trap? Gone. The system isn't held together by memory and muscle memory anymore. It's documented, automated, and reproducible — the CLAUDE.md file is more accurate than any runbook I've ever written, because it was updated in real time as every decision was made. Hardware failure is now a recovery exercise, not a rebuild from scratch.
That same principle applies whether you're working on a home project or shipping a feature in a codebase with a decade of history and a team of fifteen engineers. The tools and scale differ. The dynamic doesn't: AI removes the friction; your judgment determines whether it's worth using.
That's not AI replacing engineering. That's what happens when the friction is gone.
FAQ
What is vibe coding?
Vibe coding is an iterative, conversational workflow where the engineer drives intent and architecture while AI handles implementation details and boilerplate. It's not "prompt and ship" — the human reviews, pushes back, and makes every meaningful judgment call. The AI is a fast implementation layer and context-holder. The engineering is still yours.
Can AI replace DevOps engineers?
No. AI can generate correct Kubernetes manifests, diagnose known failure modes, and hold complex configuration in context. What it can't do is measure your environment, know when something feels wrong, or debug undocumented architecture combinations. The Dynatrace Operator conflict in this project needed a human with internal product knowledge. No amount of manifest iteration was going to find it.
What is CLAUDE.md and why does it matter?
CLAUDE.md is a living architecture document committed to the repo that the AI reads at the start of every session. It holds hardware specs, design decisions, rationale, and tradeoffs — the shared memory of the project. Without it, you rebuild context every session and the AI makes decisions that contradict earlier ones. With it, every choice you've made carries forward automatically.
How long does it take to learn Kubernetes with AI assistance?
In this project: one week of evenings to go from zero hands-on experience to understanding kustomize overlays, Sealed Secrets, Image Updater git write-back, and k3s service networking. The difference from traditional learning is you're building something real throughout, asking "why" at each step, with immediate answers scoped to your specific setup — not generic documentation examples.
Florian Lettner is Director of Developer Relations at Dynatrace. Views are my own.