

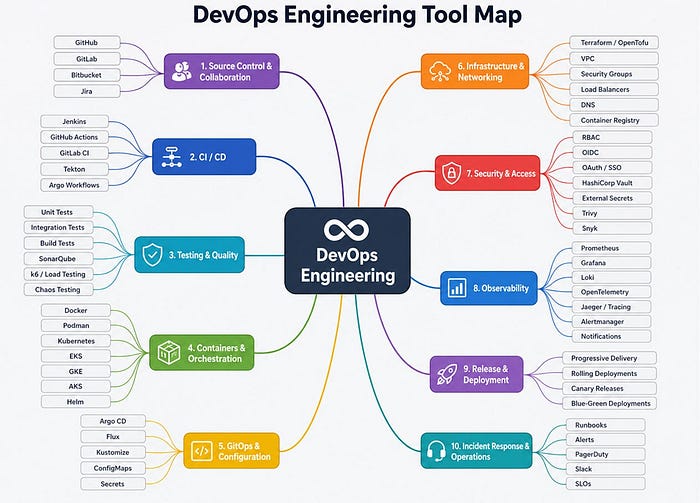
Developers are the primary actors in a software engineering organization — and with that top of mind it becomes necessary to ensure that the developer experience in an organization is the best in class.
Platform engineering emerged as an organisational response to the increase in complexity of software delivery. Internal developer platforms intend to reduce the operational burden and cognitive load placed on development teams by providing reusable workflows, self-service capabilities, standardised environments, operational guardrails, and golden paths.
Industry interest in platform engineering has grown rapidly. Gartner projected that by 2026, 80 percent of large software engineering organisations would establish platform engineering teams, compared with 45 percent in 2022. DORA describes platform engineering as a socio-technical discipline involving automation, self-service, repeatability, shared services, and golden paths. These definitions indicate that platform engineering involves more than the deployment of infrastructure or the introduction of a developer portal.
Maintaining the relationship between development and operations is core to good devops and platform engineering practices.
Declaring victory too early
Platform teams often declare success after reaching visible technical milestones.
A service can be deployed. A cluster is operational. A continuous integration and delivery pipeline exists. Developers can request infrastructure through a portal, and dashboards indicate that workloads are healthy. From an infrastructure perspective, the platform may appear complete.
Yet adoption may remain limited.
Developers continue using locally maintained scripts. Teams bypass recommended workflows. Infrastructure engineers repeatedly respond to similar support requests. Instead of reducing complexity, the platform becomes another system that developers must learn and operate.
This outcome suggests that technical availability is not equivalent to platform effectiveness. A platform can contain sophisticated infrastructure while providing limited organisational leverage.
Low adoption is frequently attributed to developer resistance. However, developers often leave the supported path because it is slower, narrower, or more difficult than their existing workflow. A platform that exposes infrastructure complexity through a portal has changed the interface without necessarily reducing the cognitive burden. Similarly, a platform that supports only idealised application patterns may be abandoned when teams encounter production requirements that the golden path does not accommodate.
Poorly designed platforms can therefore increase the distance between developers and production rather than reduce it. They may centralise control without creating meaningful self-service, standardise deployment without standardising operations, or automate individual tasks without providing a coherent end-to-end experience.
This leads to a more useful question than whether an organisation has established a platform:
Where does the organisation sit on a platform maturity scale?
Answering this question requires examining both the experience of building software and the systems required to operate it.
Three Interdependent Workframes
Platform maturity should be considered through three related workframes.
1. The Developer Experience Workframe
The developer-experience workframe concerns how effectively engineers can transform an idea or requirement into a working software change. It includes:
- discovering available platform capabilities
- creating repositories and services
- provisioning development environments
- obtaining approved dependencies
- testing changes
- deploying applications
- diagnosing failures
- accessing documentation and operational information.
A strong developer experience reduces unnecessary cognitive load while preserving appropriate autonomy. Developers should not need to understand every internal implementation detail in order to complete routine delivery tasks. Yet, the platform should support the curious.
2. The Production-Operations Workframe
The production workframe concerns the organisation's ability to operate software safely and economically. It includes:
- reliability and availability
- security and policy enforcement
- observability and incident response
- scalability and capacity planning
- governance and compliance
- cost management
- recovery and continuity
- ownership and accountability.
A platform optimised exclusively for developer speed may allow applications to reach production without sufficient operational controls. Conversely, a platform designed primarily for central governance may become too restrictive or cumbersome for development teams.
Mature platforms reconcile these workframes by providing developers with simple paths that automatically incorporate production requirements. The objective is not to remove production controls, but to embed them into reusable platform capabilities.
3. The Agent Experience Workframe
The agent-experience workframe should be coupled with the developer-experience and production-operations workframes because software delivery is increasingly performed not only by people, but also by AI agents acting on their behalf.
Agents need structured access to organisational context, platform capabilities, policies, repositories, environments, and operational signals. They also require stable interfaces, explicit permissions, bounded actions, approval points, and auditable execution paths.
A mature platform should therefore provide an agent-ready operating model in which developers express intent, agents plan and execute authorised tasks, and the control plane enforces identity, policy, state reconciliation, observability, and accountability. The agent-experience workframe does not replace developer experience; it extends it by ensuring that automation can participate safely and consistently in the same path from requirement to production.
Five-Level Platform Maturity Model
The model represents a progression from individual technical capability towards an integrated engineering system. Organisations may demonstrate characteristics from multiple levels, and maturity may vary between teams, applications, and business units. The model should therefore be used as an analytical framework rather than as a rigid classification.
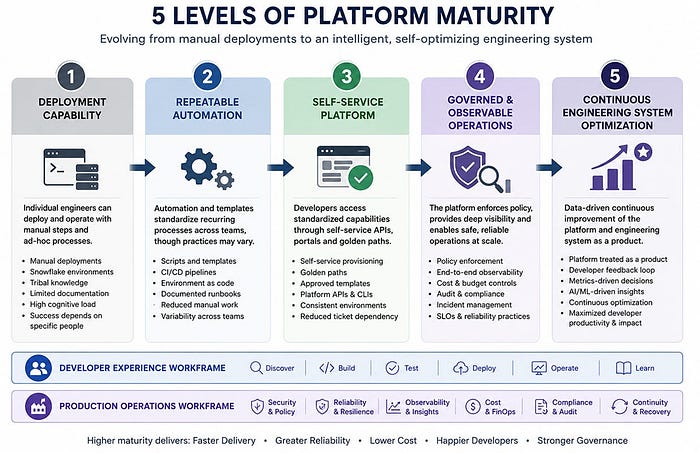
Level 1: Deployment capability
At Level 1, an application can be deployed and operated by an engineer or a small group of specialists.
Processes may rely on manual commands, undocumented conventions, copied configuration, direct infrastructure access, and individual expertise. The organisation has demonstrated technical feasibility, but successful delivery remains dependent on specific people.
This level is appropriate for prototypes, experiments, and personal systems. It should not be mistaken for an organisation-wide platform.
Level 2: Repeatable automation
At Level 2, recurring procedures are encoded through scripts, templates, build pipelines, and documented practices.
Deployment becomes more repeatable, although teams may continue maintaining their own versions of pipelines and configuration. The organisation has reduced some manual work, but developers still require substantial knowledge of the underlying infrastructure.
Automation at this level primarily reproduces existing processes. It does not necessarily provide a unified product experience.
Level 3: Self-service platform
At Level 3, developers can access common capabilities through stable APIs, command-line interfaces, declarative specifications, or developer portals.
The platform may provision repositories, environments, databases, messaging services, deployment pipelines, observability, and access controls. Organisational standards are incorporated into reusable workflows, reducing the need for tickets and direct intervention from infrastructure teams.
The transition from Level 2 to Level 3 is significant because the platform begins transferring operational capability without transferring all underlying complexity.
Level 4: Governed and observable operations
At Level 4, the platform extends beyond provisioning and deployment into continuous operational control.
It can answer questions such as:
- Who owns and operates a service?
- Which version is currently deployed?
- Which policy decisions affected the release?
- What is the service's cost and budget status?
- Which dependency or deployment preceded an incident?
- Is the service compliant with organisational requirements?
- Can it be recovered using a tested process?
Policies, telemetry, cost controls, audit evidence, and lifecycle management become integrated platform capabilities rather than external procedures applied after deployment.
Level 5: Continuous engineering-system optimisation
At Level 5, the platform is managed as a product whose users are internal development and operations teams.
The platform team evaluates adoption, task completion, developer satisfaction, lead time, deployment frequency, reliability, recovery time, platform support demand, and the frequency with which teams leave the recommended path.
The objective is no longer limited to automating infrastructure. The organisation continuously improves the overall engineering system using evidence gathered from developer behaviour and operational outcomes.
At this level, platform maturity is demonstrated by voluntary adoption and measurable organisational leverage.
Kubernetes as the Underlying Platform
Kubernetes is frequently associated with platform engineering because it provides a consistent, declarative, API-driven operating model. Its abstractions cover workloads, services, configuration, secrets, resource management, health checks, scheduling, scaling, and deployment strategies. Its extension mechanisms also allow organisations to define custom resource models and controllers.
These characteristics make Kubernetes suitable for platform automation and AI-assisted operations. Both humans and software agents can reason about desired state, observed state, and reconciliation through common APIs.
However, Kubernetes is not a prerequisite for an internal developer platform.
The same platform principles can be implemented using:
- managed container services
- serverless runtimes
- virtual machines
- platform-as-a-service products
- infrastructure APIs
- alternative schedulers
- combinations of managed cloud services.
Kubernetes becomes more compelling when the need for common definitions arise when traversing the SDLC with the intention to automate it. The library of terms used in the Kubernetes ecosystem is community approved, consistent and inline with verbal expectations — and one does not want to reinvent that.
The relevant architectural question is therefore not whether Kubernetes is intrinsically superior. It is whether its operational model provides sufficient value to justify its complexity in the organisation's context.
Behind the Scenes
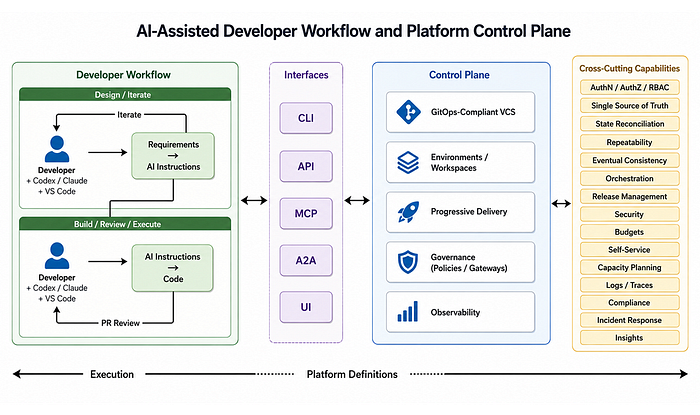
From the developer's perspective, a mature platform should present a relatively simple interface: create a service, request an environment, deploy a change, inspect a failure, or grant access. Behind that interface, however, the platform coordinates a much larger set of systems and policies.
The control plane acts as the organisational layer that connects developer intent with infrastructure execution. It receives a request, determines which policies and platform standards apply, translates the request into changes across the underlying systems, and then observes whether the desired outcome has been achieved.
A typical platform workflow may involve several steps:
- A developer or AI agent submits an intent through a portal, command-line interface, API, or repository change.
- The platform identifies the user, team, application, environment, and applicable policies.
- It validates whether the requested action is permitted.
- It generates or updates the required configuration.
- It invokes the appropriate infrastructure, delivery, security, and observability systems.
- It monitors execution and reconciles the actual state with the requested state.
- It records the decision, change, ownership, cost, and operational outcome.
The developer therefore interacts with a platform capability, while the control plane coordinates the implementation details.
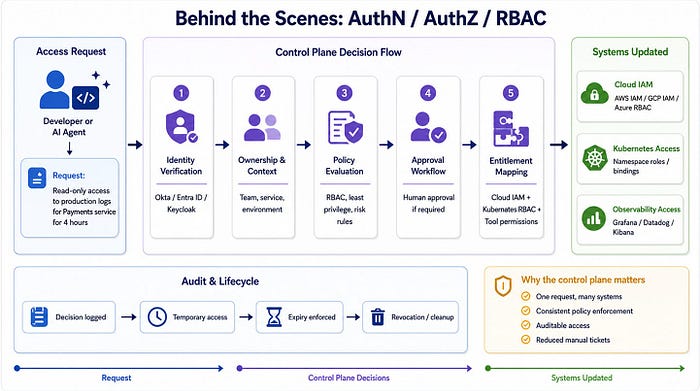
Example 1: Authentication, Authorisation, and Role-Based Access Control
Consider a developer requesting access to production logs for a payment service.
Without a platform, this request may involve a support ticket, a manually updated cloud role, changes to Kubernetes permissions, and separate configuration in the logging system. Each step may be performed by a different team, and the resulting access may remain in place longer than intended.
Through a mature platform, the developer requests the capability rather than the individual permissions:
Grant me read-only access to production logs for the payments service for the next four hours.
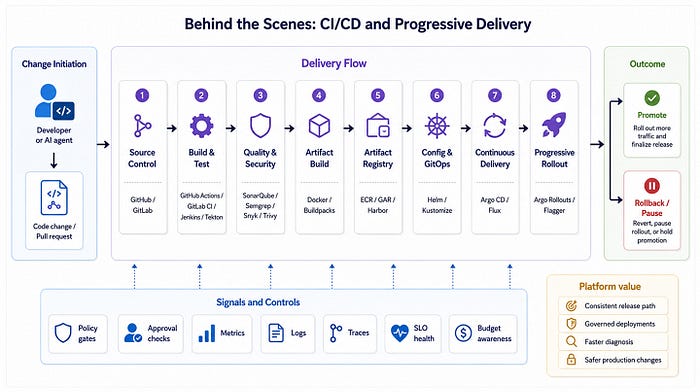
Example 2: CI/CD and Production Delivery
A similar pattern applies when a developer deploys a code change.
The visible action may be as simple as merging a pull request or selecting "Deploy to staging." Behind the scenes, the platform may coordinate source control, build automation, security checks, artifact management, GitOps, progressive delivery, and observability.
AI as an Amplifier of Platform Maturity
AI does not remove the requirement for a coherent platform. It depends on one.
An AI assistant operating across inconsistent scripts, undocumented processes, fragmented permissions, and incomplete telemetry has no reliable model of the organisation's engineering system. It may generate plausible changes without being able to determine whether those changes are safe, approved, or compatible with production requirements.
AI becomes more dependable when the platform provides:
- stable APIs
- declarative resource models
- approved templates
- policy definitions
- ownership metadata
- environment state
- change histories
- observability data
- testable workflows.
Consequently, the contribution of AI changes with platform maturity.
At Level 1, AI primarily assists individual engineers. At Level 2, it generates and maintains repeatable automation. At Level 3, it translates developer intent into approved self-service workflows. At Level 4, it interprets governance, reliability, cost, and production behaviour. At Level 5, it helps identify systemic friction and opportunities to improve the engineering organisation.
AI should therefore be understood as an amplifier. In a mature platform, it can increase access to well-defined capabilities. In an immature environment, it may automate inconsistency and accelerate the creation of operational debt.
Conclusion
Platform engineering should not be evaluated by the existence of Kubernetes, a developer portal, a service catalogue, or automated deployment pipelines. These are implementation components rather than indicators of organisational maturity.
A mature platform enables teams to deliver software through repeatable, self-service, governed, observable, and economically sustainable workflows. It aligns developer experience with production operations and evolves through continuous measurement and feedback.
Artificial intelligence can extend this model across requirements, architecture, implementation, testing, deployment, operations, cost management, and governance. Its effectiveness depends on the quality of the platform context within which it operates. Without structured workflows and controls, AI can increase the speed at which inconsistency is produced. With a mature platform, it can make organisational capabilities easier to discover, understand, and use.
Kubernetes provides one useful substrate for this model, particularly where scale, portability, extensibility, private deployment, or workload diversity justify it. It should nevertheless remain an implementation choice rather than the definition of the platform.
The final measure of platform maturity is whether engineering teams can repeatedly move from intent to production with appropriate autonomy, consistency, governance, reliability, and cost awareness — and whether they prefer the platform-supported path when doing so.
And that's what we are building through at Agumbe.
About Agumbe
Agumbe is an AI-native developer platform designed to connect developer experience, agent experience, and production operations through a common control plane. The platform helps engineering teams standardise how applications and AI workloads are created, governed, deployed, observed, and operated across environments.